databend kafka connect 构建实时数据同步
kafka connect 介绍
Kafka Connect 是一个用于在Apache Kafka®和其他数据系统之间可扩展且可靠地流式传输数据的工具。通过将数据移入和移出 Kafka 进行标准化,使得快速定义连接器以在 Kafka 中传输大型数据集变得简单,可以更轻松地构建大规模的实时数据管道。我们使用 Kafka Connector 读取或写入外部系统、管理数据流以及扩展系统,所有这些都无需开发新代码。Kafka Connect 管理与其他系统连接时的所有常见问题(Schema 管理、容错、并行性、延迟、投递语义等),每个 Connector 只关注如何在目标系统和 Kafka 之间复制数据。
Kafka 连接器通常用来构建 data pipeline,一般有两种使用场景:
开始和结束的端点:例如,将 Kafka 中的数据导出到 Databend 数据库,或者把 Mysql 数据库中的数据导入 Kafka 中。
数据传输的中间介质:例如,为了把海量的日志数据存储到 Elasticsearch 中,可以先把这些日志数据传输到 Kafka 中,然后再从 Kafka 中将这些数据导入到 Elasticsearch 中进行存储。Kafka 连接器可以作为数据管道各个阶段的缓冲区,将消费者程序和生产者程序有效地进行解耦。
Kafka connect 分为两种:
Source connect:负责将数据导入 Kafka。
Sink connect:负责将数据从 Kafka 系统中导出到目标表。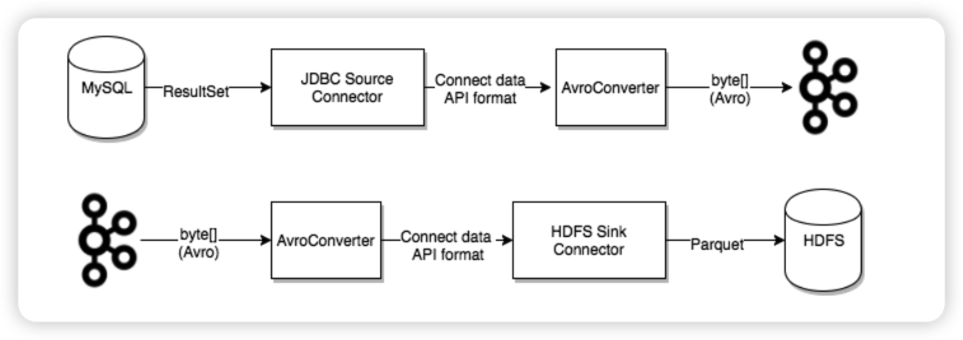
Databend Kafka Connect
Kafka 目前在 Confluent Hub 上提供了上百种 connector,比如 Elasticsearch Service Sink Connector, Amazon Sink Connector, HDFS Sink 等,用户可以使用这些 connector 以 kafka 为中心构建任意系统之间的数据管道。现在我们也为 Databend 提供了 kafka connect sink plugin,这篇文章我们将会介绍如何使用 MySQL JDBC Source Connector 和 [Databend Sink Connector] 构建实时的数据同步管道。
启动 Kafka Connect
本文假定操作的机器上已经安装 Apache Kafka,如果用户还没有安装,可以参考 Kafka quickstart 进行安装。
Kafka Connect 目前支持两种执行模式:Standalone 模式和分布式模式。
启动模式
Standalone 模式
在 Standalone 模式下,所有的工作都在单个进程中完成。这种模式更容易配置以及入门,但不能充分利用 Kafka Connect 的某些重要功能,例如,容错。我们可以使用如下命令启动 Standalone 进程:
1 | bin/connect-standalone.sh config/connect-standalone.properties connector1.properties [connector2.properties ...] |
第一个参数 config/connect-standalone.properties 是 worker 的配置。这其中包括 Kafka 连接参数、序列化格式以及提交 Offset 的频率等配置:
1 | bootstrap.servers=localhost:9092 |
后面的配置是指定要启动的 connector 的参数。
上述提供的默认配置适用于使用 config/server.properties 提供的默认配置运行的本地集群。如果使用不同配置或者在生产部署,那就需要对默认配置做调整。但无论怎样,所有 Worker(独立的和分布式的)都需要一些配置:
- bootstrap.servers:该参数列出了将要与 Connect 协同工作的 broker 服务器,Connector 将会向这些 broker 写入数据或者从它们那里读取数据。你不需要指定集群的所有 broker,但是建议至少指定3个。
- key.converter 和 value.converter:分别指定了消息键和消息值所使用的的转换器,用于在 Kafka Connect 格式和写入 Kafka 的序列化格式之间进行转换。这控制了写入 Kafka 或从 Kafka 读取的消息中键和值的格式。由于这与 Connector 没有任何关系,因此任何 Connector 可以与任何序列化格式一起使用。默认使用 Kafka 提供的 JSONConverter。有些转换器还包含了特定的配置参数。例如,通过将 key.converter.schemas.enable 设置成 true 或者 false 来指定 JSON 消息是否包含 schema。
- offset.storage.file.filename:用于存储 Offset 数据的文件。
这些配置参数可以让 Kafka Connect 的生产者和消费者访问配置、Offset 和状态 Topic。配置 Kafka Source 任务使用的生产者和 Kafka Sink 任务使用的消费者,可以使用相同的参数,但需要分别加上 ‘producer.’ 和 ‘consumer.’ 前缀。bootstrap.servers 是唯一不需要添加前缀的 Kafka 客户端参数。
distributed 模式
分布式模式可以自动平衡工作负载,并可以动态扩展(或缩减)以及提供容错。分布式模式的执行与 Standalone 模式非常相似:
1 | bin/connect-distributed.sh config/connect-distributed.properties |
不同之处在于启动的脚本以及配置参数。在分布式模式下,使用 connect-distributed.sh 来代替 connect-standalone.sh。第一个 worker 配置参数使用的是 config/connect-distributed.properties 配置文件:
1 | bootstrap.servers=localhost:9092 |
Kafka Connect 将 Offset、配置以及任务状态存储在 Kafka Topic 中。建议手动创建 Offset、配置和状态的 Topic,以达到所需的分区数和复制因子。如果在启动 Kafka Connect 时尚未创建 Topic,将使用默认分区数和复制因子来自动创建 Topic,这可能不适合我们的应用。在启动集群之前配置如下参数至关重要:
- group.id:Connect 集群的唯一名称,默认为 connect-cluster。具有相同 group id 的 worker 属于同一个 Connect 集群。需要注意的是这不能与消费者组 ID 冲突。
- config.storage.topic:用于存储 Connector 和任务配置的 Topic,默认为 connect-configs。需要注意的是这是一个只有一个分区、高度复制、压缩的 Topic。我们可能需要手动创建 Topic 以确保配置的正确,因为自动创建的 Topic 可能有多个分区或自动配置为删除而不是压缩。
- offset.storage.topic:用于存储 Offset 的 Topic,默认为 connect-offsets。这个 Topic 可以有多个分区。
- status.storage.topic:用于存储状态的 Topic,默认为 connect-status。这个 Topic 可以有多个分区。
需要注意的是在分布式模式下通过rest api来管理connector。
比如:
1 | GET /connectors – 返回所有正在运行的connector名。 |
配置 Connector
MySQL Source Connector
- 安装 MySQL Source Connector plugin
这里我们使用 Confluent 提供的 JDBC Source Connector。
从 Confluent hub 下载 Kafka Connect JDBC 插件并将 zip 文件解压到 /path/kafka/libs 目录下。
- 安装 MySQL JDBC Driver
因为 Connector 需要与数据库进行通信,所以还需要 JDBC 驱动程序。JDBC Connector 插件也没有内置 MySQL 驱动程序,需要我们单独下载驱动程序。MySQL 为许多平台提供了 JDBC 驱动程序。选择 Platform Independent 选项,然后下载压缩的 TAR 文件。该文件包含 JAR 文件和源代码。将此 tar.gz 文件的内容解压到一个临时目录。将 jar 文件(例如,mysql-connector-java-8.0.17.jar),并且仅将此 JAR 文件复制到与 kafka-connect-jdbc jar 文件相同的 libs 目录下:
1 | cp mysql-connector-j-8.0.32.jar /opt/homebrew/Cellar/kafka/3.4.0/libexec/libs/ |
- 配置 MySQL Connector
在 /path/kafka/config 下创建 mysql.properties 配置文件,并使用下面的配置:
1 | name=test-source-mysql-autoincrement |
针对配置我们这里重点介绍 mode , incrementing.column.name ,和 timestamp.column.name 几个字段。Kafka Connect MySQL JDBC Source 提供了三种增量同步模式:
- incrementing
- timestamp
- timestamp+incrementing
- 在 incrementing 模式下,每次都是根据 incrementing.column.name 参数指定的列,查询大于自上次拉取的最大id:
1 | SELECT * FROM mydb.test_kafka |
这种模式的缺点是无法捕获行上更新操作(例如,UPDATE、DELETE)的变更,因为无法增大该行的 id。
- timestamp 模式基于表上时间戳列来检测是否是新行或者修改的行。该列最好是随着每次写入而更新,并且值是单调递增的。需要使用 timestamp.column.name 参数指定时间戳列。
需要注意的是时间戳列在数据表中不能设置为 Nullable.
在 timestamp 模式下,每次都是根据 timestamp.column.name 参数指定的列,查询大于自上次拉取成功的 gmt_modified:
1 | SELECT * FROM mydb.test_kafka |
这种模式可以捕获行上 UPDATE 变更,缺点是可能造成数据的丢失。由于时间戳列不是唯一列字段,可能存在相同时间戳的两列或者多列,假设在导入第二条的过程中发生了崩溃,在恢复重新导入时,拥有相同时间戳的第二条以及后面几条数据都会丢失。这是因为第一条导入成功后,对应的时间戳会被记录已成功消费,恢复后会从大于该时间戳的记录开始同步。此外,也需要确保时间戳列是随着时间递增的,如果人为的修改时间戳列小于当前同步成功的最大时间戳,也会导致该变更不能同步。
- 仅使用 incrementing 或 timestamp 模式都存在缺陷。将 timestamp 和 incrementing 一起使用,可以充分利用 incrementing 模式不丢失数据的优点以及 timestamp 模式捕获更新操作变更的优点。需要使用
incrementing.column.name参数指定严格递增列、使用timestamp.column.name参数指定时间戳列。
1 | SELECT * FROM mydb.test_kafka |
由于 MySQL JDBC Source Connector 是基于 query-based 的数据获取方式,使用 SELECT 查询来检索数据,并没有复杂的机制来检测已删除的行,所以不支持
DELETE操作。可以使用基于 log-based 的 [Kafka Connect Debezium]。
后面的演示中会分别演示上述模式的效果。更多的配置参数可以参考 MySQL Source Configs 。
Databend Kafka Connector
- 安装 OR 编译 Databend Kafka Connector
可以从源码编译得到 jar 或者从 release 直接下载。
1 | git clone https://github.com/databendcloud/databend-kafka-connect.git & cd databend-kafka-connect |
将 databend-kafka-connect.jar 拷贝至 /path/kafka/libs 目录下。
- 安装 Databend JDBC Driver
从 Maven Central 下载最新的 databend jdbc 并拷贝至 /path/kafka/libs 目录下。
- 配置 Databend Kafka Connector
在 /path/kafka/config 下创建 mysql.properties 配置文件,并使用下面的配置:
1 | name=databend |
auto.create 和 auto.evolve 设置成 true 后会自动建表并在源表结构发生变化时同步到目标表。关于更多配置参数的介绍可以参考 databend kafka connect properties。
测试 Databend Kafka Connect
准备各个组件
- 启动 MySQL
1 | version: '2.1' |
- 启动 Databend
1 | version: '3' |
- 以 standalone 模式启动 kafka connect,并加载 MySQL Source Connector 和 Databend Sink Connector:
1 | ./bin/connect-standalone.sh config/connect-standalone.properties config/databend.properties config/mysql.properties |
1 | [2023-09-06 17:39:23,128] WARN [databend|task-0] These configurations '[metrics.context.connect.kafka.cluster.id]' were supplied but are not used yet. (org.apache.kafka.clients.consumer.ConsumerConfig:385) |
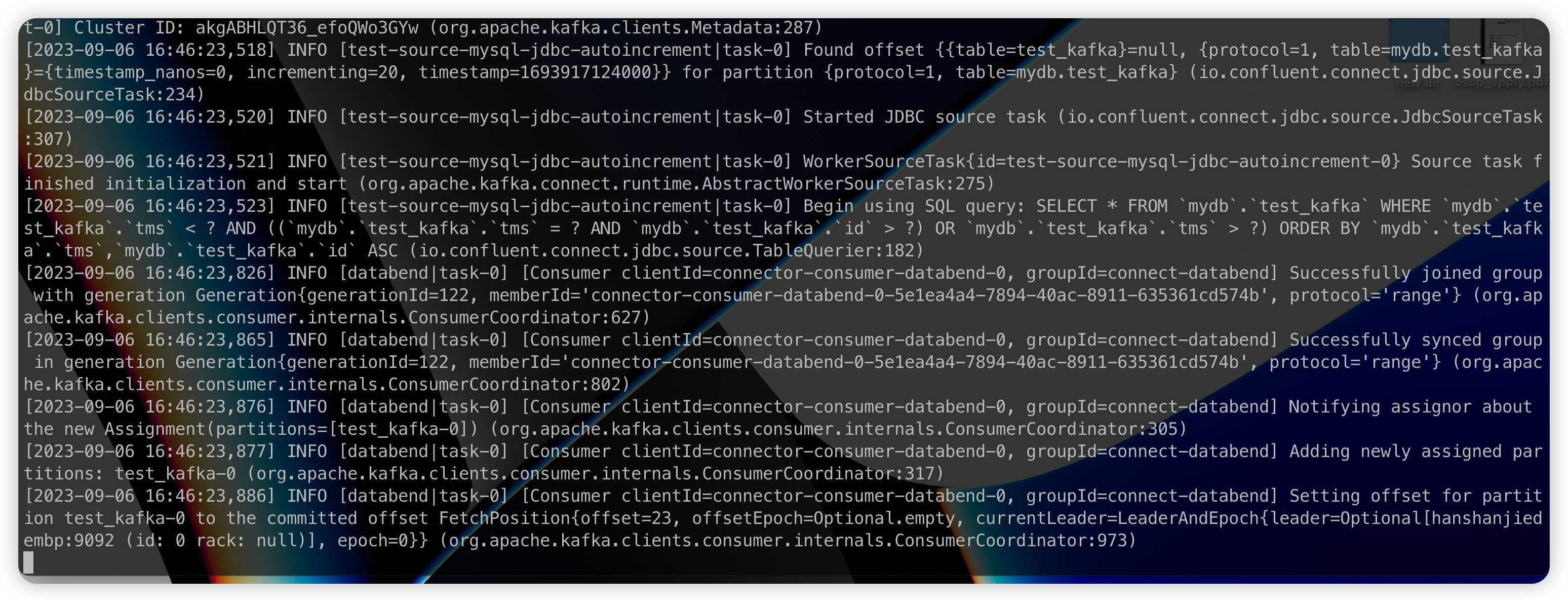
Insert
Insert 模式下我们需要使用如下的 MySQL Connector 配置:
1 | name=test-source-mysql-jdbc-autoincrement |
在 MySQL 中创建数据库 mydb 和表 test_kafka:
1 | CREATE DATABASE mydb; |
在插入数据之前,databend-kafka-connect 并不会收到 event 进行建表和数据写入:
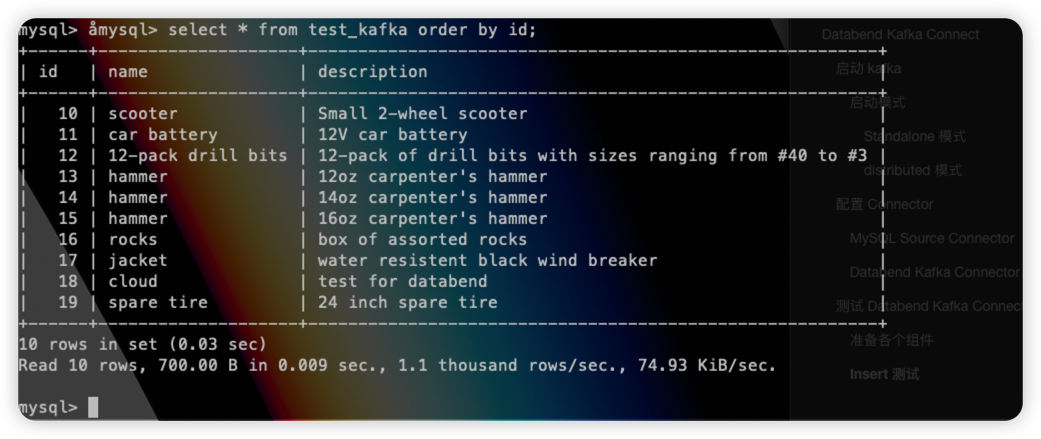
插入数据:
1 | INSERT INTO test_kafka VALUES (default,"scooter","Small 2-wheel scooter"), |
源表端插入数据后,
Databend 目标端的表就新建出来了:
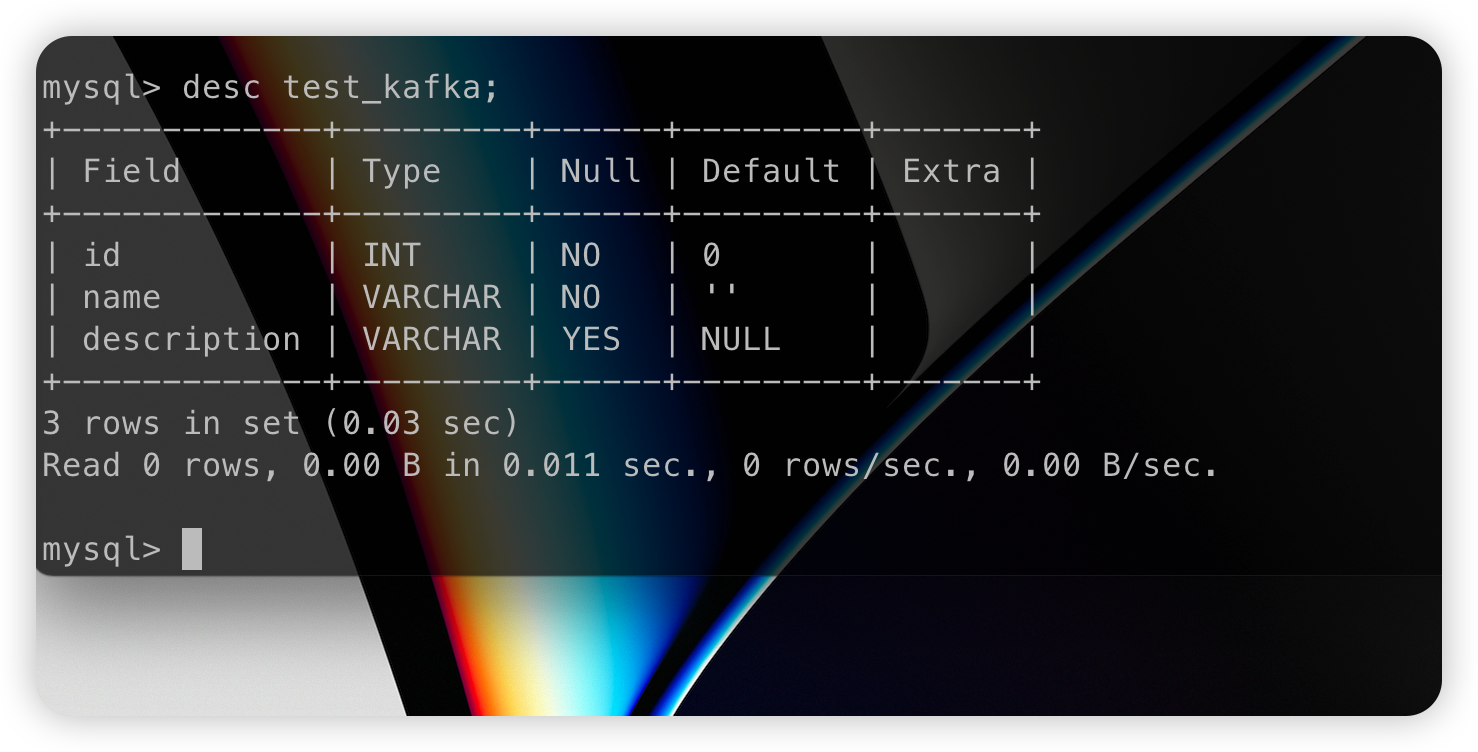
同时数据也会成功插入:
Support DDL
我们在配置文件中 auto.evolve=true,所以在源表结构发生变化的时候,会将 DDL 同步至目标表。这里我们正好需要将 MySQL Source Connector 的模式从 incrementing 改成 timestamp+incrementing,需要新增一个 timestamp 字段并打开 timestamp.column.name=tms 配置。我们在原表中执行:
1 | alter table test_kafka add column tms timestamp; |
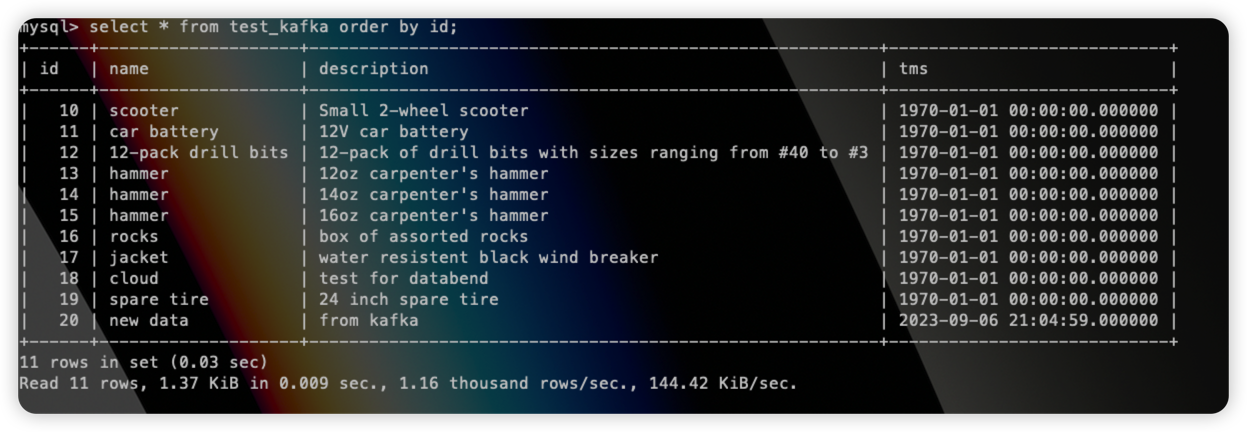
并插入一条数据:
1 | insert into test_kafka values(20,"new data","from kafka",now()); |
到目标表中查看:
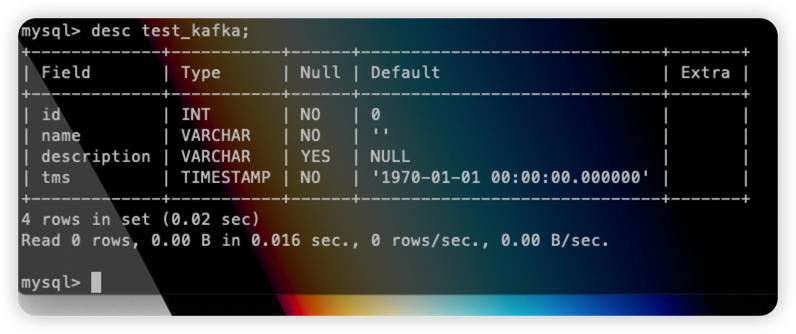
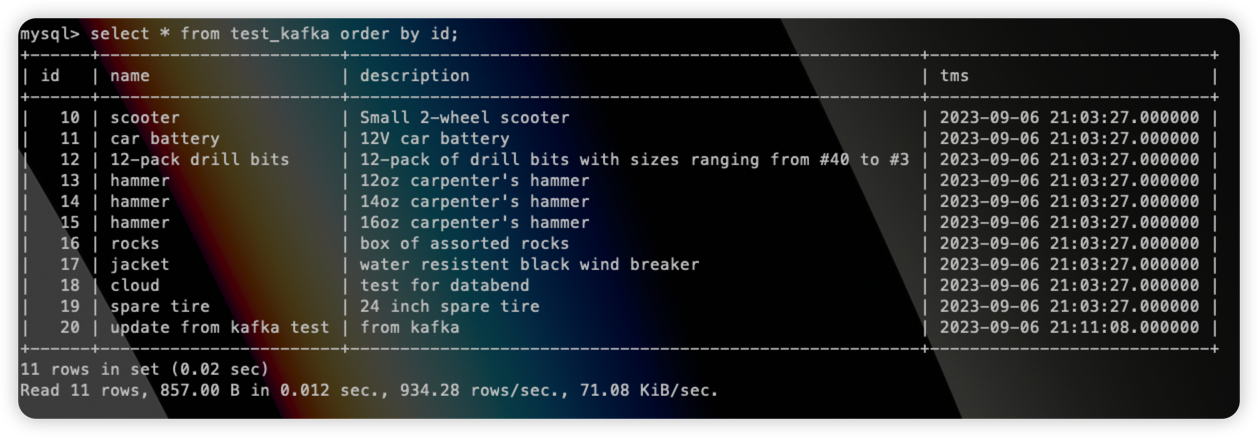
发现 tms 字段已经同步至 Databend table,并且该条数据也已经插入成功:
Upsert
修改 MySQL Connector 的配置为:
1 | name=test-source-mysql-jdbc-autoincrement |
重启 kafka connect。
在源表中更新一条数据:
1 | update test_kafka set name="update from kafka test" where id=20; |
到目标表中可以看到更新的数据:
总结
通过上面的内容可以看到 databend kafka connect 具有以下特性:
- Table 和 Column 支持自动创建:
auto.create和 `auto-evolve 的配置支持下,可以自动创建 Table 和 Column,Table name是基于 Kafka topic name 创建的; - Kafka Shemas 支持:connector 支持 Avro、JSON Schema 和 Protobuf 输入数据格式。必须启用 Schema Registry 才能使用基于 Schema Registry 的格式;
- 多个写入模式:Connector 支持
insert和upsert写入模式; - 多任务支持:在 kafka connect 的能力下,connector 支持运行一个或多个任务。增加任务的数量可以提高系统性能;
- 高可用:分布式模式下可以自动平衡工作负载,并可以动态扩展(或缩减)以及提供容错能力。
同时,Databend Kafka Connect 也能够使用原生 connect 支持的配置,更多配置参考 Kafka Connect Sink Configuration Properties for Confluent Platform。
为 Databend Rust Driver 实现 Python Binding
HOW? PyO3 + Maturin
Rust 和 Python 都拥有丰富的包和库。在 Python 中,很多包的底层是使用 C/C++ 编写的,而 Rust 天生与 C 兼容。因此,我们可以使用 Rust 为 Python 编写软件包,实现 Python 调用 Rust 的功能,从而获得更好的性能和速度。
为了实现这一目标,PyO3 应运而生。PyO3 不仅提供了 Rust 与 Python 的绑定功能,还提供了一个名为 maturin 的开箱即用的脚手架工具。通过 maturin,我们可以方便地创建基于 Rust 开发的 Python 扩展模块。这样一来,我们可以重新组织代码,使用 Rust 编写性能更好的部分,而其余部分仍然可以使用原始的 Python 代码。

Databend 目前有针对 Rust、Go、Python、Java 的多套 Driver SDK,维护成本颇高,上游一旦出现更新 SDK 便会手忙脚乱。 Rust 能提供对其他语言的 Binding 实现一套代码到处使用,而且又能获得更好地性能和速度,何乐而不为呢?
本篇文章我们关注如何在 python 中调用 Rust 开发的模块,以此来为 Databend Rust Driver 实现 Python Binding。
简单的 Demo
这里我们以官网提供的最简单的方式来做个演示。
1 | mkdir string_sum |
这个时候,我们可以得到一个简单的 Rust 项目,并且包含了调用的示例,打开 src/lib.rs:
1 | use pyo3::prelude::*; |
可以看到 pyfunction 和 pymodule 两个 Rust 的宏,#[pymodule] 过程宏属性负责将模块的初始化函数导出到Python。它可以接受模块的名称作为参数,该名称必须是.so或.pyd文件的名称;默认值为Rust函数的名称。#[pyfunction] 注释一个函数,然后使用 wrap_pyfunction 宏将其添加到刚刚定义的模块中。
我们无需修改任何代码,可以直接执行下面的命令测试:
1 | maturin develop 会自动打包出一个 wheel 包,并且安装到当前的 venv 中 |
构建 Databend Driver 的 Python Binding
初始化项目
在 bendsql 根目录下创建 bindings/python的 rust 项目:
1 | cd bendsql |
为了使用PyO3,我们需要将其作为依赖项添加到我们的Cargo.toml文件中,以及其他依赖项。我们的Cargo.toml文件应该如下所示:
1 | [package] |
PyO3 添加为依赖项,并使用适当的属性注解 Rust 函数(我们将在后面介绍),就可以使用 PyO3 库创建一个可以被导入到 Python 脚本中的 Python 扩展模块。
将 Rust Struct 转换成 Python 模块
databend-client 中提供了两种连接到 databend 的方式,flightSQL 和 http, databend-driver package 实现了一个 Trait来统一入口并自动解析协议:
bendsql/driver/src/conn.rs
1 |
|
所以我们只需要将该 Trait 转换成 Python class ,就能在 python 中调用这些方法。Pyo3 官网中提供了转换 Trait 的方式,https://pyo3.rs/v0.12.3/trait_bounds,但是这种方式过于复杂,需要写太多的胶水代码,而且对用户也不友好,不能做到开箱即用。左思右想,为何不将 Trait 封装一个 Struct 然后将 Struct 直接将转换成 python module ?
1 |
|
这里写了一个 Connector 的 struct,里面封装了 Connection Trait,为 Connector 实现了 new_connector 方法,返回的正是一个指向 Connector 的指针,更多代码可以看这里 。
在 asyncio.rs 中我们就可以定义一个 Struct AsyncDatabendDriver 暴露为 python class,并定义 python module 为 databend-driver:
1 | /// `AsyncDatabendDriver` is the entry for all public async API |
接下来就要为 AsyncDatabendDriver 实现相应的方法,而底层调用的就是 rust 中实现的 Trait 中的方法(这里以 exec 为例):
1 |
|
最后在 lib.rs 中将 AsyncDatabendDriver 添加为 python class:
1 |
|
定义 python 扩展模块信息
创建 pyproject.toml 和 python/databend_driver 并定义 python module 相关信息。
测试
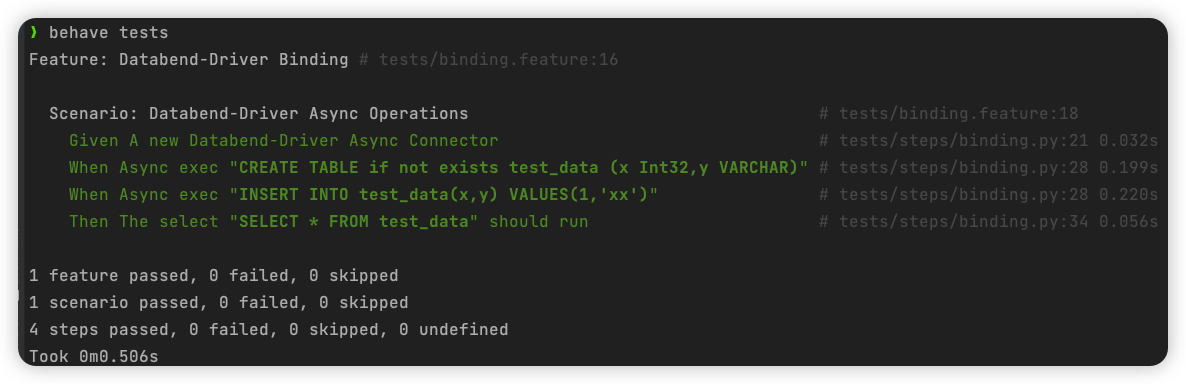
这里我们使用 behave 进行测试,同时也可以看到能够以 import databend_driver 的形式在 python 项目中使用:
1 | Feature: Databend-Driver Binding |
1 | import os |
运行 maturin develop 会自动打包出一个 wheel 包,并且安装到当前的 venv 中 ,
1 | .... |
执行 behave tests 运行测试集:
结论
基于 Pyo3,我们可以比较方便地专注于 Rust 实现逻辑本身,无需关注太多 FFI (Foreign Function Interface)和转换细节就可以将 Rust 低成本地转换成 Python 模块,后期也只需要维护一套代码,极大地降低了维护成本。本文章抛砖引玉,只是将很少部分代码做了转换,后面会陆续将 rust driver 全部提供 Python binding 最终替换掉现在的 databend-py。
HTML
2022-41 homebrew formula example for go
最近准备将 bendsql 发布到 homebrew 的 repo,这样就可以使用 brew install bendsql 方便地安装 bendsql 了。发布的方式就是为 bendsql 写一个 formula 并提 pr 到 homebrew-core,在此记录一下如何生成 homebrew formula。
说干就干, fork 了 homebrew-core 的 repo 然后 checkout 分支准备提 PR。
执行 brew create $download_URL 执行后会生成 install 模板,根据模板填写需要的信息。
1 | class Bendsql < Formula |
根据 homebrew-core 的文档,在提 PR 之前要完成几个前置操作:
当执行到 brew test bendsql 的时候,发现向 homebrew 官方仓库提交应用是需要满足一定条件的:
bendsql 刚开源一周还没满足以上条件,所以没法直接使用 brew install bendsql,只能另辟蹊径了。
想起来之前写其他工具的时候,只要在自己的账户中创建一个 homebrew-tap 的 repo, 比如 https://github.com/hantmac/homebrew-tap, 就能实现类似的下载效果。
所以只要在 databendcloud 的账户下,新建一个这样的 repo,将上面配好的 formula 提交进去就可以 brew tap databendcloud/homebrew-tap && brew install bendsql 很方便地下载了。