sync.WaitGroup Overview
Go 作为云原生开发的代表,以其在并发编程中的易用性而闻名。在大多数情况下,人们会在处理并发时使用 WaitGroup。我经常想要了解它是如何工作的,所以本文主要谈谈我对 WaitGroup 的理解。
在 Go 语言中,sync.WaitGroup 允许主程序或其他 goroutines 在继续执行之前等待多个 goroutines 执行完毕。
它主要用于以下情况:
等待一组执行程序完成:当我们有多个并发任务需要执行,并希望在所有这些任务完成后继续执行后续操作时。
确保资源释放:在并发操作中,为了避免资源竞争和数据不一致,有必要在释放资源前确保所有 goroutine 都已执行完毕。
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package main
import (
"fmt"
"sync"
)
func main() {
var counter int64
var mu sync.Mutex
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
for j := 0; j < 1000; j++ {
mu.Lock()
counter++
mu.Unlock()
}
wg.Done()
}()
}
wg.Wait()
fmt.Println("Final Counter:", counter)
}
sync.WaitGroup in Go 1.17:
Go 1.20 之前的结构有一些巧妙的地方,因此本文将以 Go 1.17 为例重点讲解。
1 | type WaitGroup struct { |
- nocopy 是一种防止结构被复制的保护机制,将在后面介绍。
- state1 主要存储计数状态和 semaphore,我们接下来将重点讨论。
要理解注释的内容,首先需要了解内存对齐方式,以及在 Add() 和 Wait() 中如何使用 state1。
内存对齐要求数据地址必须是某个值的倍数,这可以提高 CPU 读取内存数据的效率:
- 32 位对齐:数据的起始地址必须是 4 的倍数
- 64 位对齐:数据的起始地址必须是 8 的倍数
在 Add() 和 Wait() 中,计数器和等待器合并为一个 64 位整数使用。1
2
3
4
5statep, semap := wg.state()
...
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
当需要更改计数器和等待器的值时,64 位整数会通过原子方式进行原子操作。但原子中你有一些需要注意的使用点,golang 官方文档 sync/atomic/PKG - note - bugs 中就有这样的内容:
在 ARM、386 和 32 位 MIPS 上,调用者有责任安排通过原始原子函数原子访问的 64 位字的 64 位对齐(Int64 和 Uint64 类型自动对齐)。分配的结构体、数组或片段中的第一个字;全局变量中的第一个字;或局部变量中的第一个字(因为所有原子操作的对象都会逃逸到堆中)都可以依赖于 64 位对齐。
基于这一前提,在 32 位系统中,我们需要自己保证 “count+waiter “的 64 位对齐。那么问题来了,如果是你来实现,该如何写呢?
state()
让我们来看下官方的实现:1
2
3
4
5
6
7
8
9
10state1 [3]uint32
// state returns pointers to the state and sema fields stored within wg.state1.
func (wg *WaitGroup) state()(statep *uint64, semap *uint32) {
if uintptr(unsafe.Pointer(&wg.state1)) % 8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
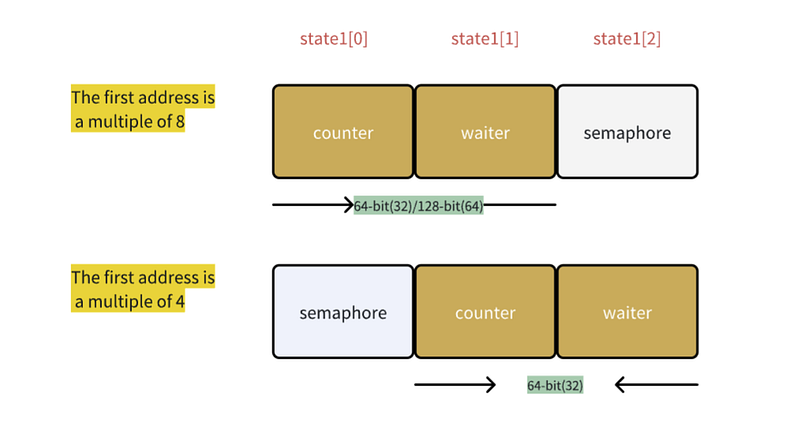
如图所示:
在 64 位系统上,都符合 8 字节对齐要求。而在 32 位系统上,也可能是这样。
在不符合 8 字节对齐要求的 32 位系统上,sema 字段向前移动 4 个字节,以确保状态字段符合 8 字节对齐要求。
只需重新安排 sema 字段的位置,我们就能保证计数器+等待器始终对齐 64 位边界,这确实非常聪明。
简化实现流程
现在,让我们考虑一下原始结构,为简单起见,忽略内存对齐和并发安全因素:1
2
3
4
5type WaitGroup struct {
counter int32
waiter uint32
sema uint32
}
计数器表示尚未完成的任务数。WaitGroup.Add(n)将导致计数器 += n,而 WaitGroup.Done() 将导致计数器–。
waiter 表示调用了 WaitGroup.Wait 的程序数目。
sema 对应 Go 运行时的内部信号实现。在 WaitGroup 中,我们使用了两个相关函数:runtime_Semacquire 和 runtime_Semrelease。runtime_Semacquire 会增加一个 semaphore 并暂停当前的 goroutine。
注意,这只是一个简化的实施过程,实际代码可能更加复杂。
Add()、Done()、Wait()
可以先阅读下这段代码 cs.opensource.google/go/go/+/refs/tags/go1.17:src/sync/waitgroup.go
结合我们常见的使用场景,关键流程如下:
调用 WaitGroup.Add(n) 时,计数器将按 n 递增: counter += n
1 | state := atomic.AddUint64(statep, uint64(delta)<<32) |
在调用 WaitGroup.Wait() 时,它将递增 waiter++ 并调用 runtime_Semacquire(semap) 来增加 semaphore 并暂停当前的 goroutine。
1 | if atomic.CompareAndSwapUint64(statep, state, state+1) { |
当调用 WaitGroup.Done() 时,它将递减计数器–。如果递减后的计数器等于 0,则表示 WaitGroup 的等待进程已经结束,我们需要调用 runtime_Semrelease 来释放 semaphore,并唤醒 WaitGroup.Wait 上等待的程序。
1 | for ; w != 0; w-- { |
Go 1.20 中的 WaitGroup
cs.opensource.google/go/go/+/refs/tags/go1.20:src/sync/waitgroup.go
相信有人已经注意到了一个问题,即计数器和等待器在更改时需要确保并发安全。为什么不直接使用 atomic.Uint64 呢?
这是因为 atomic.Uint64 只在 1.17 以后的版本中才受支持。
在 Go 1.20 中,我们可以注意到内存对齐逻辑被 atomic.Uint64 所取代,虽然在 Go 1.20 的发布说明中没有提及,但我们可以从中学习到很多东西。
Reference: sync: use atomic.Uint64 for WaitGroup state
noCopy
在 waitGroup 结构中,我们看到了 noCopy。为什么需要 noCopy?让我们来看一个例子:
1 | package main |
在 Go 中,指针复制是一种浅层复制,即只复制顶层结构。如果原始结构及其副本都指向相同的底层数据,这可能会导致意想不到的行为。如果一个结构的数据被修改,可能会影响到另一个结构。
使用 noCopy 字段有助于进行静态编译检查。使用 go vet,可以检查对象或对象中的字段是否已被复制。
关于 WaitGroup 的说明
探索使用 WaitGroup 时的一些限制和潜在隐患,并学习如何避免这些问题。
如果你看过 Go 源代码,可能会注意到下面这些总结要点的经典注释:
Add() 操作必须在 Wait() 操作之前执行。
调用 Done() 的次数必须与 Add() 设置的计数器值一致。
如果计数器的值小于 0,就会出现 panic
不能同时调用 Add() 和 Wait();例如,在两个不同的程序中调用这两个函数会导致 panic。
必须等到 Wait() 完成后,才能对 WaitGroup 进行后续调用。
Semaphores
在上一节中,我们提到了semaphores,它是一种保护共享资源和防止多个线程同时访问同一资源的机制。让我们来看看 Semaphores 在 Unix/Linux 系统中是如何工作的:
一个 Semaphore 包含一个非负整数变量和两个原子操作:等待(下)和信号(上)。等待操作也可称为 P 或 down,它将值递减 1;而信号操作也称为 V 或 up,它将值递增 1。 Semaphores 使用原子操作来实现对并发资源的控制。
等待(P,向下)操作:如果 semaphore 的非负整数变量 S > 0,wait 将递减它;如果 S = 0,wait 将阻塞线程。
信号(V,向上)操作:递增后,如果递增前的值为负数(表示有进程在等待资源),则被阻塞的进程将从 semaphore 的等待队列移到就绪队列;如果没有线程被阻塞在 semaphore 上,则 signal 会简单地在 S 上加 1。
这与 Go 中使用 WaitGroup 的常见情况一致:
首先使用 runtime_Semacquire(semap)执行 Wait(),这样会将 semap 设置为 0,并增加 semaphore 和暂停当前程序。
当所有运行程序都完成了 Done() 执行后,执行 runtime_Semrelease 以释放寄存器,并唤醒 WaitGroup.Wait 上等待的运行程序。
1 | //go:linkname sync_runtime_Semacquire sync.runtime_Semacquire |
例如,让我们来看看 semacquire1(等待、P、向下):
尝试获取信号:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if cansemacquire(addr) {
return
}
func cansemacquire(addr *uint32) bool {
for {
v := atomic.Load(addr)
if v == 0 {
return false
}
if atomic.Cas(addr, v, v-1) {
return true
}
}
}阻止并等待:
1
2
3
4
5
6
7
8
9
10
11
12
13
14for {
...
if cansemacquire(addr) {
root.nwait.Add(-1)
unlock(&root.lock)
break
}
root.queue(addr, s, lifo)
goparkunlock(&root.lock, reason, traceBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
...
}


