分布式数据库 severless 服务要点
最近在读一些分布式数据库 serverless 服务化的文章,从中总结出一些构建此类服务面临的痛点以及如何破局的要点,算是一个读书笔记。主要参考的文章有 cockroachdb severless 解读, How we built a forever-free serverless SQL database。
大致内容提纲

为什么要云原生数据库
数据库的 scale 能力决定了这个产品的上限,而一家公司能用多少人服务多少客户的 scale 能力,决定了公司营收的上限。而破局的方式就是数据库上云,把数据库的服务化,降低门槛。
为什么要 serverless 化
serverless 卖服务的形式,一个集群就可以服务”无穷”个租户,只要没有实际的使用,并不会产生成本。多增加一个租户,它的边际成本是零。所以这个模式是 scalable 的。
而为了实现 serverless 的目的,云原生数据库的架构大多是存储和计算分离的。
多租户的资源隔离问题
如果是多租户共享计算层和存储层,那复杂 SQL 就会将整个集群的资源耗尽,影响其他租户;
如果是每个租户独享各自的计算层和存储层,也就是回到了每个租户一套集群的模式,成本非常高。
综上因素,比较好的方式是独享计算层,共享存储层。上层的 SQL 是租户之间物理隔离的,下面的 kv 存储是由所有租户去共享的。
共享存储之后,如何区分租户数据
共享存储层后,可以在请求的 key 的编码中添加 tenant-id,多租户模式下,SQL 的表的数据映射成 kv 数据,最终的编码是 /tenant-id/table-id/index-id/key。
集群架构
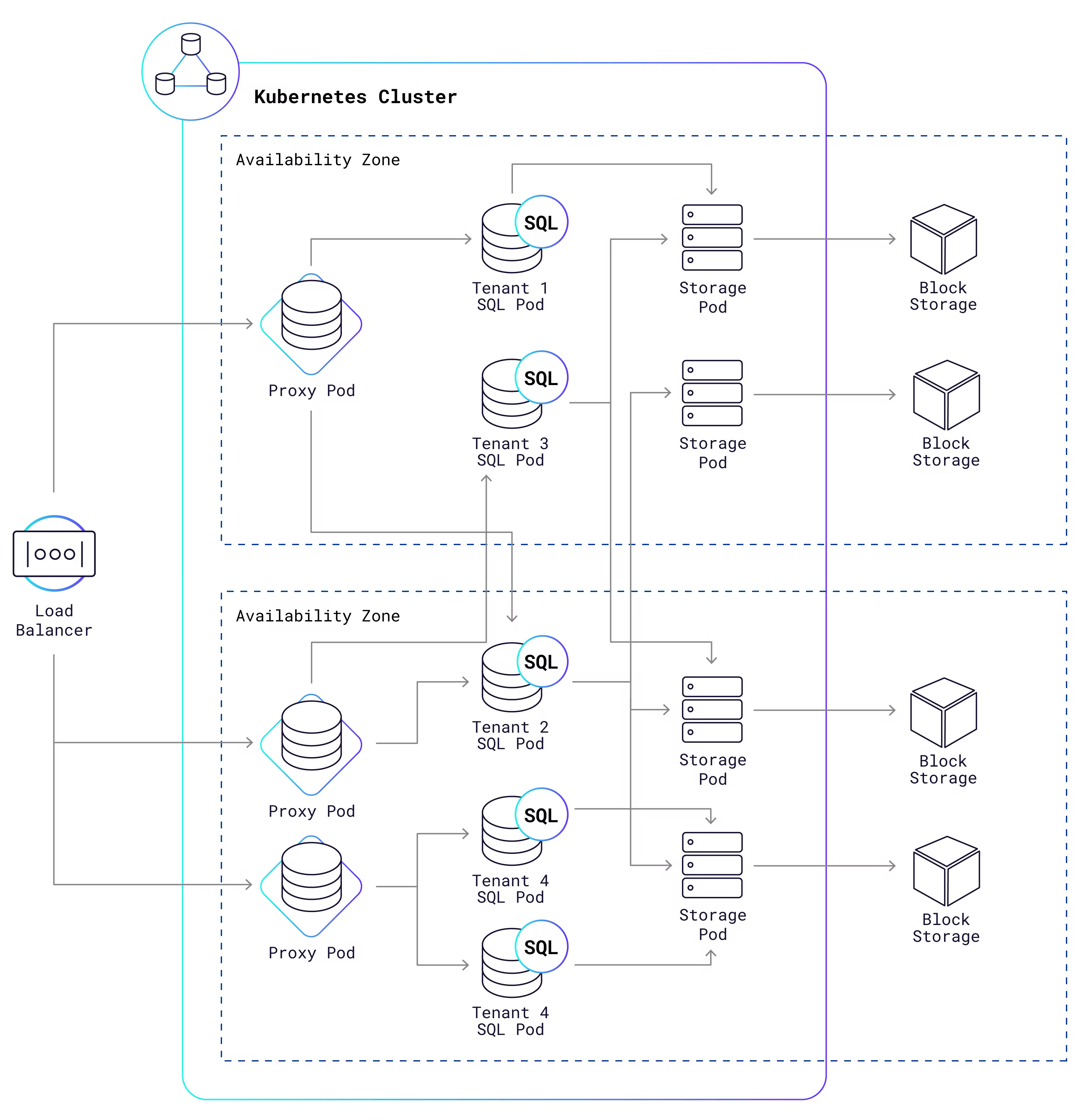
名词解释
Block storage: 多租户共享的存储
SQL Pod: 租户独享的 SQL 计算节点
Proxy Pod : 负责将租户的请求路由到正确的 SQL 节点上
计算节点无状态,这意味着 SQL pod 可以随用随起,也就是说,当某个 tenant 没有流量时,完全可以把它的 SQL 节点停下关掉,需要的时候再动态拉起。
以上。


